1. 개요
클릭률 예측은 광고의 입찰가 결정에 지대한 영향을 끼치고, 이는 곧 매출과 직결되어 있다. 따라서 사용자와 방문 페이지에 따른 광고 클릭 확률을 추정하는 것은 매우 중요한 문제이다. 이번 예측 대회에서는 특정 고객이 특정 사이트에 접속했을 때 특정 광고를 클릭할 확률을 예측해보는 대회이다.

같은 학회원인 이해환, 권다희와 함께 대회에 참가했으나, 결론적으로 말하면 우리팀은 예측율이 턱없이 부족해 본선에는 진출하지 못하였다.
그러나 그 과정이 매우 원만했고 팀의 합이 잘 맞았으며 또 새로이 배운 것이 많았기에 아쉬움이 많았던 대회였다.
따라서 우리는 포스팅을 통해 배운 것을 정리하고 부족한 부분을 점검하여 다음 대회를 위한 준비를 하기로 했다.
아래는 팀원들의 깃헙 블로그 주소이다.
2. 주요 초점
대회의 데이터 셋은 고객의 아이디와 기타 접속상황이 저장 되어 있는 Train Data와 그 고객의 각종 정보가 저장되어 있는 Audience_Profile 두가지로 이루어져 있었다.
고객의 중요한 정보가 들어있는 데이터 이므로 모든 명목형 자료들은 암호화를 거쳐서 전달되었다.
이 데이터 셋으로 예측모델을 짜기 위해서는 몇가지 핵심 문제들을 해결해주었어야 했다.
첫 번째, 대용량 처리
Train 데이터의 경우 550만개의 자료가 24개의 변수를 가지고 있었다. 심지어 그 중 20개가 “WD23SLDC” 따위의 암호화 변수였으므로 데이터의 크기는 1.5Gb에 달했다. 거기에 더해, Audience_Profile 자료는 약 1000만개의 자료가 저장되어 있었고 파일크기는 9Gb에 달하는 자료였다.
두 자료 모두 로컬에서는 돌리기가 힘든 자료였다. 데이터를 라벨인코딩 등을 이용하여 축소시키고, 불필요한 자료를 버림으로써 로컬에서 핸들링은 가능하였으나, 실제 알고리즘을 돌릴 때는 메모리가 턱없이 부족했다.
따라서 우리는 구글 Colab에서 지원하는 25Gb의 메모리자원을 사용하였으나, 차후에 언급할 알고리즘들은 이 정도로도 부족해 GCP의 n1-Highmem-32 (메모리 320Gb)를 사용했다. 이를 위한 GCP 사용법은 아래에 링크로 달아놓았다.

두 번째, 자연어 처리
Audience 데이터의 경우 사용자가 설치한 어플리케이션 항목과 IGAworks에서 매긴 사용자의 카테고리 정보가 변수로 있었다. 그러나 이 변수들은 여러가지 Str 항목이 하나의 리스트에 합쳐져 있는 꼴이었고, 심지어 자료간에 겹치는 항목들도 적었다.
따라서 이를 처리해주는 작업이 급선무였고 처리 후 여러 분석을 통해 새로운 변수를 만들어내는 것도 큰일이었다. 따라서 같은 팀의 이해환,권다희가 이 일을 전담하였다. 이에 대한 포스팅 또한 아래에 링크로 달아놓았다.
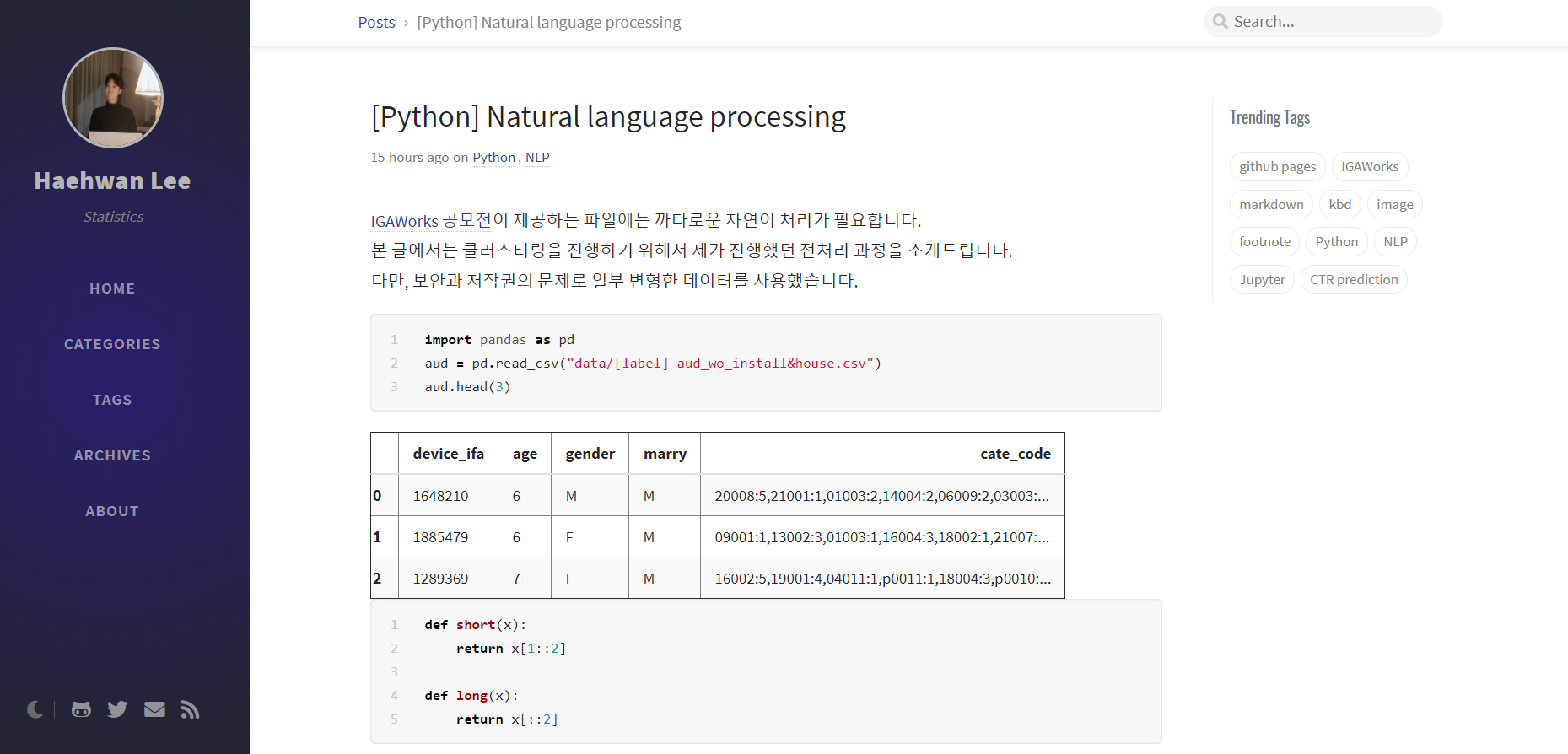
세 번째, 차원축소
Train 데이터의 경우 전술했듯 20개의 변수가 명목형 자료 였는데 이를 모두 더미화를 하면 변수가 무려 3만개에 달했다. 이러한 데이터를 컴퓨터에서 다룰 수 없을뿐더러, 오버피팅이 당연히 발생할 것이므로 차원축소가 Train 데이터의 주요화두였다. 따라서 우리는 처음에는 단순 EDA와 군집분석을 활용하였으나 오버피팅이 발생하여 두 번째로 MCA방법을 이용하였다.
그러나 결론적으로 볼 때, 우리가 예선을 통과하지 못했던 것은 이 부분에 대한 처리가 미숙했기 때문으로 보인다. 실제로 같은 대회에 나간 다른 학회원들은 Cat-Boost나 딥러닝의 Embedding Layer를 이용하여 처리해주었다. 둘 모두 현재 머신러닝의 최신기술이며 내가 사용한 방법들은 조금 더 고전적인 방법이다. 이 부분에 대해서는 아래의 링크에 더 자세하게 포스팅을 해두었다.

네 번째, 알고리즘의 최적화
요즘 머신러닝의 기법들이 매우 빠른 속도로 갱신되고 있기에 사실은 점수를 올리기 위해서는 최신 기법을 서술한 코드를 이해없이 Ctrl+C , Ctrl+V 해주는게 점수를 올리기위한 최적의 전략이라 할수 있다. 그러나 우리팀은 모두가 통계대학원 진학을 생각하고 있고, 또 제대로 이해한 알고리즘을 커스텀해서 써주는 것이 발전을 위해서라도 더 바람직한 길으로 생각했기에 베이지안 옵티마이제이션을 사용하기로 했다.
결론적으로 예선을 통과하진 못했지만, 만약 본선에서 발표를 할 때 제대로 이해한 알고리즘을 제대로 피로하는것은 분명한 메리트가 될 것이다.
이러한 네가지 포인트가 이번대회 우리팀의 주요 화두였다. 이 네가지를 핵심으로 많은 회의를 하고 미팅을 가졌다. 비록 다른 팀에 비해 결과물은 좋지 않았지만 대회를 통해 우리 팀보다 많은 것을 배운 팀은 없으리라 자부한다.
3. 발표자료
아래는 본선에는 진출하지 못했지만 우리 팀의 결과물을 시각적으로 정리하기 위해 만들어본 발표자료이다.
4. 한계와 개선점
첫번째, 차원축소 방식
우리는 본선진출을 포기할 정도로 점수가 나오지 않은 상태라 제출을 아예 하지 않았다. 그래도 몇가지 변명을 해보자면, 내부자료를 이용한 Cross-Validation의 결과는 logloss기준 test스코어가 0.235에 달했으나 테스트 셋으로 예측해낸 결과물은 리더보드에서 0.25를 넘지 못하였다. 참고로 리더보드 1등 팀의 점수는 0.238이었다.
원인은 알 수 없고 추정밖에 할 수 없으나, 아마 차원축소의 알고리즘이 테스트 데이터에는 언더피팅이 되었으리라고 생각된다. 다음에는 이러한 일이 없게 하기위해 우리팀에서는 내가 이 부분을 계속 공부해나갈 것이다.
두번째, 최신기술 탐구
전술했듯, 우리가 사용한 기법들은 다소 오래된 것이었다. 이는 우리가 충분히 이해하지 못하는 알고리즘을 쓰는 것에 대한 심적 거부감에 기인한 것으로 보인다. 따라서 앞으로는 최신논문을 계속해서 탐구할 필요가 있어 보인다.
그렇다고 오래된 기법을 버릴 생각은 없다. 구식 기법은 우리가 충분히 이해할 수 있을 뿐더러 연구가 충분히 진행되어 있기에 결과물의 해석에 있어서 큰 강점을 가지고 있기 때문이다.
따라서 둘 모두를 병행해서 사용하며 성능은 최신으로, 해석은 구식 기법을 이용하는 것이 적절한 방식으로 보인다.
세번째, 소통의 방식
소통의 방식이 덜 체계적이었던 것 같다. 한 팀원이 겪은 문제를 해결하면 다른 팀원은 똑같은 문제를 겪지 않아야 할텐데 같은 문제를 3명 모두가 겪은 일이 있었다. 또 한 팀원이 진행한 방식을 다른 팀원은 모르고 있어 반영이 늦은 일도 있었다.
이는 각자 역할을 나누어 놓고 다른 팀원들은 그다지 간섭을 하지 않았기 때문으로 보인다. 따라서 다음부터는 이를 방지하기 위해서 현재 진행상황, 에러발생, 해결책, 처리 방법에 대한 체계적인 게시판이 만드려 한다.
이는 비단 다음 대회를 위해서인 것 뿐만 아니라 컴퓨터를 이용한 팀프로젝트 전반에 필요한 습관인 것 같다.
5. 결론
많은 좌절이 있었던 대회다. 너무나도 좋은 팀원을 만났고 또 많은 것을 배웠음에도 불구하고 결과물이 좋지 않았기 때문이다.
그럼에도 불구하고 우리팀은 다시 뭉치기로 했다.
다음 대회는 반드시 좋은 성과물을 거둘 것이다.
좌절하지 않고 과정의 중요성을 믿다보면 언제가는 더 큰 결과물을 얻을 수 있을 것이다.
Quitter never win and Winner never quit - Vinc Lombardi